Basics and working with Flows
Dependency
To use Pekko Streams, add the module to your project:
- sbt
val PekkoVersion = "1.0.1" libraryDependencies += "org.apache.pekko" %% "pekko-stream" % PekkoVersion- Maven
<properties> <scala.binary.version>2.13</scala.binary.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>org.apache.pekko</groupId> <artifactId>pekko-bom_${scala.binary.version}</artifactId> <version>1.0.1</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.apache.pekko</groupId> <artifactId>pekko-stream_${scala.binary.version}</artifactId> </dependency> </dependencies>- Gradle
def versions = [ ScalaBinary: "2.13" ] dependencies { implementation platform("org.apache.pekko:pekko-bom_${versions.ScalaBinary}:1.0.1") implementation "org.apache.pekko:pekko-stream_${versions.ScalaBinary}" }
Introduction
Core concepts
Pekko Streams is a library to process and transfer a sequence of elements using bounded buffer space. This latter property is what we refer to as boundedness, and it is the defining feature of Pekko Streams. Translated to everyday terms, it is possible to express a chain (or as we see later, graphs) of processing entities. Each of these entities executes independently (and possibly concurrently) from the others while only buffering a limited number of elements at any given time. This property of bounded buffers is one of the differences from the actor model, where each actor usually has an unbounded, or a bounded, but dropping mailbox. Pekko Stream processing entities have bounded “mailboxes” that do not drop.
Before we move on, let’s define some basic terminology which will be used throughout the entire documentation:
- Stream
- An active process that involves moving and transforming data.
- Element
- An element is the processing unit of streams. All operations transform and transfer elements from upstream to downstream. Buffer sizes are always expressed as number of elements independently from the actual size of the elements.
- Back-pressure
- A means of flow-control, a way for consumers of data to notify a producer about their current availability, effectively slowing down the upstream producer to match their consumption speeds. In the context of Pekko Streams back-pressure is always understood as non-blocking and asynchronous.
- Non-Blocking
- Means that a certain operation does not hinder the progress of the calling thread, even if it takes a long time to finish the requested operation.
- Graph
- A description of a stream processing topology, defining the pathways through which elements shall flow when the stream is running.
- Operator
- The common name for all building blocks that build up a Graph. Examples of operators are
map(),filter(), custom ones extendingGraphStages and graph junctions likeMergeorBroadcast. For the full list of built-in operators see the operator index
When we talk about asynchronous, non-blocking backpressure, we mean that the operators available in Pekko Streams will not use blocking calls but asynchronous message passing to exchange messages between each other. This way they can slow down a fast producer without blocking its thread. This is a thread-pool friendly design, since entities that need to wait (a fast producer waiting on a slow consumer) will not block the thread but can hand it back for further use to an underlying thread-pool.
Defining and running streams
Linear processing pipelines can be expressed in Pekko Streams using the following core abstractions:
- Source
- An operator with exactly one output, emitting data elements whenever downstream operators are ready to receive them.
- Sink
- An operator with exactly one input, requesting and accepting data elements, possibly slowing down the upstream producer of elements.
- Flow
- An operator which has exactly one input and output, which connects its upstream and downstream by transforming the data elements flowing through it.
- RunnableGraph
- A Flow that has both ends “attached” to a Source and Sink respectively, and is ready to be
run().
It is possible to attach a FlowFlow to a SourceSource resulting in a composite source, and it is also possible to prepend a Flow to a SinkSink to get a new sink. After a stream is properly constructed by having both a source and a sink, it will be represented by the RunnableGraphRunnableGraph type, indicating that it is ready to be executed.
It is important to remember that even after constructing the RunnableGraph by connecting all the source, sink and different operators, no data will flow through it until it is materialized. Materialization is the process of allocating all resources needed to run the computation described by a Graph (in Pekko Streams this will often involve starting up Actors). Thanks to Flows being a description of the processing pipeline they are immutable, thread-safe, and freely shareable, which means that it is for example safe to share and send them between actors, to have one actor prepare the work, and then have it be materialized at some completely different place in the code.
- Scala
-
source
val source = Source(1 to 10) val sink = Sink.fold[Int, Int](0)(_ + _) // connect the Source to the Sink, obtaining a RunnableGraph val runnable: RunnableGraph[Future[Int]] = source.toMat(sink)(Keep.right) // materialize the flow and get the value of the sink val sum: Future[Int] = runnable.run() - Java
-
source
final Source<Integer, NotUsed> source = Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)); // note that the Future is scala.concurrent.Future final Sink<Integer, CompletionStage<Integer>> sink = Sink.fold(0, Integer::sum); // connect the Source to the Sink, obtaining a RunnableFlow final RunnableGraph<CompletionStage<Integer>> runnable = source.toMat(sink, Keep.right()); // materialize the flow final CompletionStage<Integer> sum = runnable.run(system);
After running (materializing) the RunnableGraph[T] we get back the materialized value of type T. Every stream operator can produce a materialized value, and it is the responsibility of the user to combine them to a new type. In the above example, we used toMat to indicate that we want to transform the materialized value of the source and sink, and we used the convenience function Keep.right to say that we are only interested in the materialized value of the sink.
In our example, the Sink.fold materializes a value of type Future which will represent the result of the folding process over the stream. In general, a stream can expose multiple materialized values, but it is quite common to be interested in only the value of the Source or the Sink in the stream. For this reason there is a convenience method called runWith() available for Sink, Source or Flow requiring, respectively, a supplied Source (in order to run a Sink), a Sink (in order to run a Source) or both a Source and a Sink (in order to run a Flow, since it has neither attached yet).
After running (materializing) the RunnableGraph we get a special container object, the MaterializedMap. Both sources and sinks are able to put specific objects into this map. Whether they put something in or not is implementation dependent.
For example, a Sink.fold will make a CompletionStage available in this map which will represent the result of the folding process over the stream. In general, a stream can expose multiple materialized values, but it is quite common to be interested in only the value of the Source or the Sink in the stream. For this reason there is a convenience method called runWith() available for Sink, Source or Flow requiring, respectively, a supplied Source (in order to run a Sink), a Sink (in order to run a Source) or both a Source and a Sink (in order to run a Flow, since it has neither attached yet).
- Scala
-
source
val source = Source(1 to 10) val sink = Sink.fold[Int, Int](0)(_ + _) // materialize the flow, getting the Sink's materialized value val sum: Future[Int] = source.runWith(sink) - Java
-
source
final Source<Integer, NotUsed> source = Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)); final Sink<Integer, CompletionStage<Integer>> sink = Sink.fold(0, Integer::sum); // materialize the flow, getting the Sink's materialized value final CompletionStage<Integer> sum = source.runWith(sink, system);
It is worth pointing out that since operators are immutable, connecting them returns a new operator, instead of modifying the existing instance, so while constructing long flows, remember to assign the new value to a variable or run it:
- Scala
-
source
val source = Source(1 to 10) source.map(_ => 0) // has no effect on source, since it's immutable source.runWith(Sink.fold(0)(_ + _)) // 55 val zeroes = source.map(_ => 0) // returns new Source[Int], with `map()` appended zeroes.runWith(Sink.fold(0)(_ + _)) // 0 - Java
-
source
final Source<Integer, NotUsed> source = Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)); source.map(x -> 0); // has no effect on source, since it's immutable source.runWith(Sink.fold(0, Integer::sum), system); // 55 // returns new Source<Integer>, with `map()` appended final Source<Integer, NotUsed> zeroes = source.map(x -> 0); final Sink<Integer, CompletionStage<Integer>> fold = Sink.fold(0, Integer::sum); zeroes.runWith(fold, system); // 0
By default, Pekko Streams elements support exactly one downstream operator. Making fan-out (supporting multiple downstream operators) an explicit opt-in feature allows default stream elements to be less complex and more efficient. Also, it allows for greater flexibility on how exactly to handle the multicast scenarios, by providing named fan-out elements such as broadcast (signals all down-stream elements) or balance (signals one of available down-stream elements).
In the above example we used the runWith method, which both materializes the stream and returns the materialized value of the given sink or source.
Since a stream can be materialized multiple times, the materialized value will also be calculated anew MaterializedMap returned is different for each such materialization, usually leading to different values being returned each time. In the example below, we create two running materialized instances of the stream that we described in the runnable variable. Both materializations give us a different FutureCompletionStage from the map even though we used the same sink to refer to the future:
- Scala
-
source
// connect the Source to the Sink, obtaining a RunnableGraph val sink = Sink.fold[Int, Int](0)(_ + _) val runnable: RunnableGraph[Future[Int]] = Source(1 to 10).toMat(sink)(Keep.right) // get the materialized value of the sink val sum1: Future[Int] = runnable.run() val sum2: Future[Int] = runnable.run() // sum1 and sum2 are different Futures! - Java
-
source
// connect the Source to the Sink, obtaining a RunnableGraph final Sink<Integer, CompletionStage<Integer>> sink = Sink.fold(0, Integer::sum); final RunnableGraph<CompletionStage<Integer>> runnable = Source.from(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).toMat(sink, Keep.right()); // get the materialized value of the FoldSink final CompletionStage<Integer> sum1 = runnable.run(system); final CompletionStage<Integer> sum2 = runnable.run(system); // sum1 and sum2 are different Futures!
Defining sources, sinks and flows
The objects SourceSource and SinkSink define various ways to create sources and sinks of elements. The following examples show some of the most useful constructs (refer to the API documentation for more details):
- Scala
-
source
// Create a source from an Iterable Source(List(1, 2, 3)) // Create a source from a Future Source.future(Future.successful("Hello Streams!")) // Create a source from a single element Source.single("only one element") // an empty source Source.empty // Sink that folds over the stream and returns a Future // of the final result as its materialized value Sink.fold[Int, Int](0)(_ + _) // Sink that returns a Future as its materialized value, // containing the first element of the stream Sink.head // A Sink that consumes a stream without doing anything with the elements Sink.ignore // A Sink that executes a side-effecting call for every element of the stream Sink.foreach[String](println(_)) - Java
-
source
// Create a source from an Iterable List<Integer> list = new LinkedList<>(); list.add(1); list.add(2); list.add(3); Source.from(list); // Create a source form a Future Source.future(Futures.successful("Hello Streams!")); // Create a source from a single element Source.single("only one element"); // an empty source Source.empty(); // Sink that folds over the stream and returns a Future // of the final result in the MaterializedMap Sink.fold(0, Integer::sum); // Sink that returns a Future in the MaterializedMap, // containing the first element of the stream Sink.head(); // A Sink that consumes a stream without doing anything with the elements Sink.ignore(); // A Sink that executes a side-effecting call for every element of the stream Sink.foreach(System.out::println);
There are various ways to wire up different parts of a stream, the following examples show some of the available options:
- Scala
-
source
// Explicitly creating and wiring up a Source, Sink and Flow Source(1 to 6).via(Flow[Int].map(_ * 2)).to(Sink.foreach(println(_))) // Starting from a Source val source = Source(1 to 6).map(_ * 2) source.to(Sink.foreach(println(_))) // Starting from a Sink val sink: Sink[Int, NotUsed] = Flow[Int].map(_ * 2).to(Sink.foreach(println(_))) Source(1 to 6).to(sink) // Broadcast to a sink inline val otherSink: Sink[Int, NotUsed] = Flow[Int].alsoTo(Sink.foreach(println(_))).to(Sink.ignore) Source(1 to 6).to(otherSink) - Java
-
source
// Explicitly creating and wiring up a Source, Sink and Flow Source.from(Arrays.asList(1, 2, 3, 4)) .via(Flow.of(Integer.class).map(elem -> elem * 2)) .to(Sink.foreach(System.out::println)); // Starting from a Source final Source<Integer, NotUsed> source = Source.from(Arrays.asList(1, 2, 3, 4)).map(elem -> elem * 2); source.to(Sink.foreach(System.out::println)); // Starting from a Sink final Sink<Integer, NotUsed> sink = Flow.of(Integer.class).map(elem -> elem * 2).to(Sink.foreach(System.out::println)); Source.from(Arrays.asList(1, 2, 3, 4)).to(sink);
Illegal stream elements
In accordance to the Reactive Streams specification (Rule 2.13) Pekko Streams do not allow null to be passed through the stream as an element. In case you want to model the concept of absence of a value we recommend using scala.Option or scala.util.Eitherjava.util.Optional which is available since Java 8.
Back-pressure explained
Pekko Streams implement an asynchronous non-blocking back-pressure protocol standardised by the Reactive Streams specification, which Pekko is a founding member of.
The user of the library does not have to write any explicit back-pressure handling code — it is built in and dealt with automatically by all of the provided Pekko Streams operators. It is possible however to add explicit buffer operators with overflow strategies that can influence the behavior of the stream. This is especially important in complex processing graphs which may even contain loops (which must be treated with very special care, as explained in Graph cycles, liveness and deadlocks).
The back pressure protocol is defined in terms of the number of elements a downstream Subscriber is able to receive and buffer, referred to as demand. The source of data, referred to as Publisher in Reactive Streams terminology and implemented as SourceSource in Pekko Streams, guarantees that it will never emit more elements than the received total demand for any given Subscriber.
The Reactive Streams specification defines its protocol in terms of Publisher and Subscriber. These types are not meant to be user facing API, instead they serve as the low-level building blocks for different Reactive Streams implementations.
Pekko Streams implements these concepts as SourceSource, FlowFlow (referred to as Processor in Reactive Streams) and SinkSink without exposing the Reactive Streams interfaces directly. If you need to integrate with other Reactive Stream libraries, read Integrating with Reactive Streams.
The mode in which Reactive Streams back-pressure works can be colloquially described as “dynamic push / pull mode”, since it will switch between push and pull based back-pressure models depending on the downstream being able to cope with the upstream production rate or not.
To illustrate this further let us consider both problem situations and how the back-pressure protocol handles them:
Slow Publisher, fast Subscriber
This is the happy case – we do not need to slow down the Publisher in this case. However signalling rates are rarely constant and could change at any point in time, suddenly ending up in a situation where the Subscriber is now slower than the Publisher. In order to safeguard from these situations, the back-pressure protocol must still be enabled during such situations, however we do not want to pay a high penalty for this safety net being enabled.
The Reactive Streams protocol solves this by asynchronously signalling from the Subscriber to the Publisher Request(n:Int) Request(int n) signals. The protocol guarantees that the Publisher will never signal more elements than the signalled demand. Since the Subscriber however is currently faster, it will be signalling these Request messages at a higher rate (and possibly also batching together the demand - requesting multiple elements in one Request signal). This means that the Publisher should not ever have to wait (be back-pressured) with publishing its incoming elements.
As we can see, in this scenario we effectively operate in so called push-mode since the Publisher can continue producing elements as fast as it can, since the pending demand will be recovered just-in-time while it is emitting elements.
Fast Publisher, slow Subscriber
This is the case when back-pressuring the Publisher is required, because the Subscriber is not able to cope with the rate at which its upstream would like to emit data elements.
Since the Publisher is not allowed to signal more elements than the pending demand signalled by the Subscriber, it will have to abide to this back-pressure by applying one of the below strategies:
- not generate elements, if it is able to control their production rate,
- try buffering the elements in a bounded manner until more demand is signalled,
- drop elements until more demand is signalled,
- tear down the stream if unable to apply any of the above strategies.
As we can see, this scenario effectively means that the Subscriber will pull the elements from the Publisher – this mode of operation is referred to as pull-based back-pressure.
Stream Materialization
When constructing flows and graphs in Pekko Streams think of them as preparing a blueprint, an execution plan. Stream materialization is the process of taking a stream description (RunnableGraphRunnableGraph) and allocating all the necessary resources it needs in order to run. In the case of Pekko Streams this often means starting up Actors which power the processing, but is not restricted to that—it could also mean opening files or socket connections etc.—depending on what the stream needs.
Materialization is triggered at so called “terminal operations”. Most notably this includes the various forms of the run() and runWith() methods defined on SourceSource and FlowFlow elements as well as a small number of special syntactic sugars for running with well-known sinks, such as runForeach(el => ...)runForeach(el -> ...) (being an alias to runWith(Sink.foreach(el => ...))runWith(Sink.foreach(el -> ...))).
Materialization is performed synchronously on the materializing thread by an ActorSystemActorSystem global MaterializerMaterializer. The actual stream processing is handled by actors started up during the streams materialization, which will be running on the thread pools they have been configured to run on - which defaults to the dispatcher set in the ActorSystem config or provided as attributes on the stream that is getting materialized.
Reusing instances of linear computation operators (Source, Sink, Flow) inside composite Graphs is legal, yet will materialize that operator multiple times.
Operator Fusion
By default, Pekko Streams will fuse the stream operators. This means that the processing steps of a flow or stream can be executed within the same Actor and has two consequences:
- passing elements from one operator to the next is a lot faster between fused operators due to avoiding the asynchronous messaging overhead
- fused stream operators do not run in parallel to each other, meaning that only up to one CPU core is used for each fused part
To allow for parallel processing you will have to insert asynchronous boundaries manually into your flows and operators by way of adding Attributes.asyncBoundaryAttributes.asyncBoundary using the method async on SourceSource, SinkSink and FlowFlow to operators that shall communicate with the downstream of the graph in an asynchronous fashion.
- Scala
-
source
Source(List(1, 2, 3)).map(_ + 1).async.map(_ * 2).to(Sink.ignore) - Java
-
source
Source.range(1, 3).map(x -> x + 1).async().map(x -> x * 2).to(Sink.ignore());
In this example we create two regions within the flow which will be executed in one Actor each—assuming that adding and multiplying integers is an extremely costly operation this will lead to a performance gain since two CPUs can work on the tasks in parallel. It is important to note that asynchronous boundaries are not singular places within a flow where elements are passed asynchronously (as in other streaming libraries), but instead attributes always work by adding information to the flow graph that has been constructed up to this point:
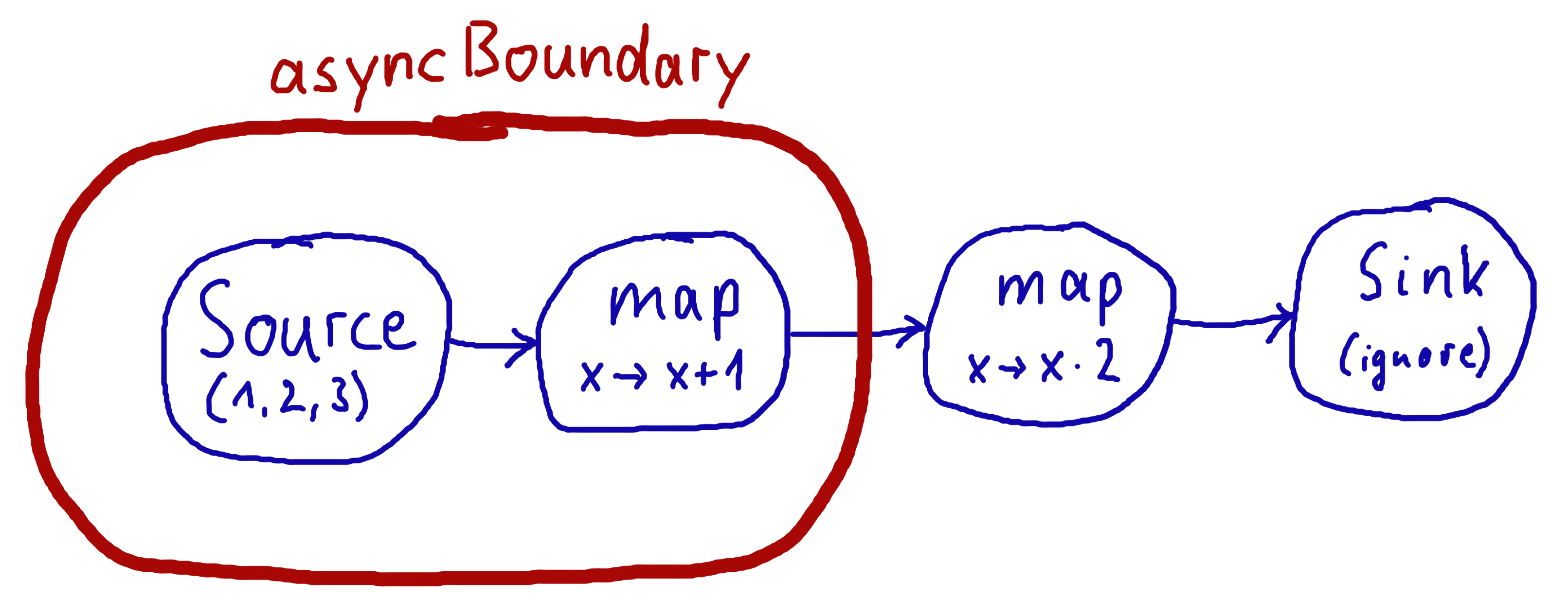
This means that everything that is inside the red bubble will be executed by one actor and everything outside of it by another. This scheme can be applied successively, always having one such boundary enclose the previous ones plus all operators that have been added since then.
Without fusing (i.e. up to version 2.0-M2) each stream operator had an implicit input buffer that holds a few elements for efficiency reasons. If your flow graphs contain cycles then these buffers may have been crucial in order to avoid deadlocks. With fusing these implicit buffers are no longer there, data elements are passed without buffering between fused operators. In those cases where buffering is needed in order to allow the stream to run at all, you will have to insert explicit buffers with the .buffer() operator—typically a buffer of size 2 is enough to allow a feedback loop to function.
Combining materialized values
Since every operator in Pekko Streams can provide a materialized value after being materialized, it is necessary to somehow express how these values should be composed to a final value when we plug these operators together. For this, many operator methods have variants that take an additional argument, a function, that will be used to combine the resulting values. Some examples of using these combiners are illustrated in the example below.
- Scala
-
source
// A source that can be signalled explicitly from the outside val source: Source[Int, Promise[Option[Int]]] = Source.maybe[Int] // A flow that internally throttles elements to 1/second, and returns a Cancellable // which can be used to shut down the stream val flow: Flow[Int, Int, Cancellable] = throttler // A sink that returns the first element of a stream in the returned Future val sink: Sink[Int, Future[Int]] = Sink.head[Int] // By default, the materialized value of the leftmost stage is preserved val r1: RunnableGraph[Promise[Option[Int]]] = source.via(flow).to(sink) // Simple selection of materialized values by using Keep.right val r2: RunnableGraph[Cancellable] = source.viaMat(flow)(Keep.right).to(sink) val r3: RunnableGraph[Future[Int]] = source.via(flow).toMat(sink)(Keep.right) // Using runWith will always give the materialized values of the stages added // by runWith() itself val r4: Future[Int] = source.via(flow).runWith(sink) val r5: Promise[Option[Int]] = flow.to(sink).runWith(source) val r6: (Promise[Option[Int]], Future[Int]) = flow.runWith(source, sink) // Using more complex combinations val r7: RunnableGraph[(Promise[Option[Int]], Cancellable)] = source.viaMat(flow)(Keep.both).to(sink) val r8: RunnableGraph[(Promise[Option[Int]], Future[Int])] = source.via(flow).toMat(sink)(Keep.both) val r9: RunnableGraph[((Promise[Option[Int]], Cancellable), Future[Int])] = source.viaMat(flow)(Keep.both).toMat(sink)(Keep.both) val r10: RunnableGraph[(Cancellable, Future[Int])] = source.viaMat(flow)(Keep.right).toMat(sink)(Keep.both) // It is also possible to map over the materialized values. In r9 we had a // doubly nested pair, but we want to flatten it out val r11: RunnableGraph[(Promise[Option[Int]], Cancellable, Future[Int])] = r9.mapMaterializedValue { case ((promise, cancellable), future) => (promise, cancellable, future) } // Now we can use pattern matching to get the resulting materialized values val (promise, cancellable, future) = r11.run() // Type inference works as expected promise.success(None) cancellable.cancel() future.map(_ + 3) // The result of r11 can be also achieved by using the Graph API val r12: RunnableGraph[(Promise[Option[Int]], Cancellable, Future[Int])] = RunnableGraph.fromGraph(GraphDSL.createGraph(source, flow, sink)((_, _, _)) { implicit builder => (src, f, dst) => import GraphDSL.Implicits._ src ~> f ~> dst ClosedShape }) - Java
-
source
// An empty source that can be shut down explicitly from the outside Source<Integer, CompletableFuture<Optional<Integer>>> source = Source.<Integer>maybe(); // A flow that internally throttles elements to 1/second, and returns a Cancellable // which can be used to shut down the stream Flow<Integer, Integer, Cancellable> flow = throttler; // A sink that returns the first element of a stream in the returned Future Sink<Integer, CompletionStage<Integer>> sink = Sink.head(); // By default, the materialized value of the leftmost stage is preserved RunnableGraph<CompletableFuture<Optional<Integer>>> r1 = source.via(flow).to(sink); // Simple selection of materialized values by using Keep.right RunnableGraph<Cancellable> r2 = source.viaMat(flow, Keep.right()).to(sink); RunnableGraph<CompletionStage<Integer>> r3 = source.via(flow).toMat(sink, Keep.right()); // Using runWith will always give the materialized values of the stages added // by runWith() itself CompletionStage<Integer> r4 = source.via(flow).runWith(sink, system); CompletableFuture<Optional<Integer>> r5 = flow.to(sink).runWith(source, system); Pair<CompletableFuture<Optional<Integer>>, CompletionStage<Integer>> r6 = flow.runWith(source, sink, system); // Using more complex combinations RunnableGraph<Pair<CompletableFuture<Optional<Integer>>, Cancellable>> r7 = source.viaMat(flow, Keep.both()).to(sink); RunnableGraph<Pair<CompletableFuture<Optional<Integer>>, CompletionStage<Integer>>> r8 = source.via(flow).toMat(sink, Keep.both()); RunnableGraph< Pair<Pair<CompletableFuture<Optional<Integer>>, Cancellable>, CompletionStage<Integer>>> r9 = source.viaMat(flow, Keep.both()).toMat(sink, Keep.both()); RunnableGraph<Pair<Cancellable, CompletionStage<Integer>>> r10 = source.viaMat(flow, Keep.right()).toMat(sink, Keep.both()); // It is also possible to map over the materialized values. In r9 we had a // doubly nested pair, but we want to flatten it out RunnableGraph<Cancellable> r11 = r9.mapMaterializedValue( (nestedTuple) -> { CompletableFuture<Optional<Integer>> p = nestedTuple.first().first(); Cancellable c = nestedTuple.first().second(); CompletionStage<Integer> f = nestedTuple.second(); // Picking the Cancellable, but we could also construct a domain class here return c; });
In Graphs it is possible to access the materialized value from inside the stream. For details see Accessing the materialized value inside the Graph.
Source pre-materialization
There are situations in which you require a SourceSource materialized value before the Source gets hooked up to the rest of the graph. This is particularly useful in the case of “materialized value powered” Sources, like Source.queue, Source.actorRef or Source.maybe.
By using the preMaterializepreMaterialize operator on a Source, you can obtain its materialized value and another Source. The latter can be used to consume messages from the original Source. Note that this can be materialized multiple times.
- Scala
-
source
val completeWithDone: PartialFunction[Any, CompletionStrategy] = { case Done => CompletionStrategy.immediately } val matValuePoweredSource = Source.actorRef[String]( completionMatcher = completeWithDone, failureMatcher = PartialFunction.empty, bufferSize = 100, overflowStrategy = OverflowStrategy.fail) val (actorRef, source) = matValuePoweredSource.preMaterialize() actorRef ! "Hello!" // pass source around for materialization source.runWith(Sink.foreach(println)) - Java
-
source
Source<String, ActorRef> matValuePoweredSource = Source.actorRef( elem -> { // complete stream immediately if we send it Done if (elem == Done.done()) return Optional.of(CompletionStrategy.immediately()); else return Optional.empty(); }, // never fail the stream because of a message elem -> Optional.empty(), 100, OverflowStrategy.fail()); Pair<ActorRef, Source<String, NotUsed>> actorRefSourcePair = matValuePoweredSource.preMaterialize(system); actorRefSourcePair.first().tell("Hello!", ActorRef.noSender()); // pass source around for materialization actorRefSourcePair.second().runWith(Sink.foreach(System.out::println), system);
Stream ordering
In Pekko Streams, almost all computation operators preserve input order of elements. This means that if inputs {IA1,IA2,...,IAn} “cause” outputs {OA1,OA2,...,OAk} and inputs {IB1,IB2,...,IBm} “cause” outputs {OB1,OB2,...,OBl} and all of IAi happened before all IBi then OAi happens before OBi.
This property is even upheld by async operations such as mapAsyncmapAsync, however an unordered version exists called mapAsyncUnorderedmapAsyncUnordered which does not preserve this ordering.
However, in the case of Junctions which handle multiple input streams (e.g. Merge) the output order is, in general, not defined for elements arriving on different input ports. That is a merge-like operation may emit Ai before emitting Bi, and it is up to its internal logic to decide the order of emitted elements. Specialized elements such as Zip however do guarantee their outputs order, as each output element depends on all upstream elements having been signalled already – thus the ordering in the case of zipping is defined by this property.
If you find yourself in need of fine grained control over order of emitted elements in fan-in scenarios consider using MergePreferred, MergePrioritized or GraphStage – which gives you full control over how the merge is performed.
Actor Materializer Lifecycle
The MaterializerMaterializer is a component that is responsible for turning the stream blueprint into a running stream and emitting the “materialized value”. An ActorSystemActorSystem wide Materializer is provided by the Pekko Extension SystemMaterializerSystemMaterializer by having an implicit ActorSystem in scopepassing the ActorSystem to the various run methods this way there is no need to worry about the Materializer unless there are special requirements.
The use case that may require a custom instance of Materializer is when all streams materialized in an actor should be tied to the Actor lifecycle and stop if the Actor stops or crashes.
An important aspect of working with streams and actors is understanding a Materializer’s life-cycle. The materializer is bound to the lifecycle of the ActorRefFactoryActorRefFactory it is created from, which in practice will be either an ActorSystemActorSystem or ActorContextActorContext (when the materializer is created within an ActorActor).
Tying it to the ActorSystem should be replaced with using the system materializer.
When run by the system materializer the streams will run until the ActorSystem is shut down. When the materializer is shut down before the streams have run to completion, they will be terminated abruptly. This is a little different than the usual way to terminate streams, which is by cancelling/completing them. The stream lifecycles are bound to the materializer like this to prevent leaks, and in normal operations you should not rely on the mechanism and rather use KillSwitchKillSwitch or normal completion signals to manage the lifecycles of your streams.
If we look at the following example, where we create the Materializer within an Actor:
- Scala
-
source
final class RunWithMyself extends Actor { implicit val mat: Materializer = Materializer(context) Source.maybe.runWith(Sink.onComplete { case Success(done) => println(s"Completed: $done") case Failure(ex) => println(s"Failed: ${ex.getMessage}") }) def receive = { case "boom" => context.stop(self) // will also terminate the stream } } - Java
-
source
final class RunWithMyself extends AbstractActor { Materializer mat = Materializer.createMaterializer(context()); @Override public void preStart() throws Exception { Source.repeat("hello") .runWith( Sink.onComplete( tryDone -> { System.out.println("Terminated stream: " + tryDone); }), mat); } @Override public Receive createReceive() { return receiveBuilder() .match( String.class, p -> { // this WILL terminate the above stream as well context().stop(self()); }) .build(); } }
In the above example we used the ActorContextActorContext to create the materializer. This binds its lifecycle to the surrounding ActorActor. In other words, while the stream we started there would under normal circumstances run forever, if we stop the Actor it would terminate the stream as well. We have bound the stream’s lifecycle to the surrounding actor’s lifecycle. This is a very useful technique if the stream is closely related to the actor, e.g. when the actor represents a user or other entity, that we continuously query using the created stream – and it would not make sense to keep the stream alive when the actor has terminated already. The streams termination will be signalled by an “Abrupt termination exception” signaled by the stream.
You may also cause a Materializer to shut down by explicitly calling shutdown()shutdown() on it, resulting in abruptly terminating all of the streams it has been running then.
Sometimes, however, you may want to explicitly create a stream that will out-last the actor’s life. For example, you are using a Pekko stream to push some large stream of data to an external service. You may want to eagerly stop the Actor since it has performed all of its duties already:
- Scala
-
source
final class RunForever(implicit val mat: Materializer) extends Actor { Source.maybe.runWith(Sink.onComplete { case Success(done) => println(s"Completed: $done") case Failure(ex) => println(s"Failed: ${ex.getMessage}") }) def receive = { case "boom" => context.stop(self) // will NOT terminate the stream (it's bound to the system!) } } - Java
-
source
final class RunForever extends AbstractActor { private final Materializer materializer; public RunForever(Materializer materializer) { this.materializer = materializer; } @Override public void preStart() throws Exception { Source.repeat("hello") .runWith( Sink.onComplete( tryDone -> { System.out.println("Terminated stream: " + tryDone); }), materializer); } @Override public Receive createReceive() { return receiveBuilder() .match( String.class, p -> { // will NOT terminate the stream (it's bound to the system!) context().stop(self()); }) .build(); }
In the above example we pass in a materializer to the Actor, which results in binding its lifecycle to the entire ActorSystemActorSystem rather than the single enclosing actor. This can be useful if you want to share a materializer or group streams into specific materializers, for example because of the materializer’s settings etc.
Do not create new actor materializers inside actors by passing the context.systemcontext.system() to it. This will cause a new MaterializerMaterializer to be created and potentially leaked (unless you shut it down explicitly) for each such actor. It is instead recommended to either pass-in the Materializer or create one using the actor’s context.